




By Muhammad Abutahir
Serverless Password Manager using AWS KMS and Amazon DynamoDB Part-3
This blog is independent of the previous blog, if you are looking only for data modeling with DynamoDB, you can still read through it.
Also, check out the following blogs:
Alright with that said, let’s get started. From the previous blog, we got a fair idea about DynamoDB and its key features, in this blog I will talk about how to come up with a data model that fits our application’s needs. I will go through my story of how I designed my data model.
What is Data Modeling?
Whenever we design an application, the first thing we need to think about beforehand is how we are going to store our data, because once the data model is designed, coming up with APIs is a piece of cake. Trust me, all the rest APIs are generally coupled with CRUD operations on DB, accessing and manipulating the data is simple. Hence the primary focus of any developer or an engineer is coming up with that magic data model which lets us access the data very smoothly. Modeling the data is like creating the blueprint of the application.
Data modeling with Relational databases
When it comes to relational databases, developers generally create different tables for different entities, while this keeps the data clean and separate, it also has many drawbacks. Duplication of data is one of them, also there are other issues like performance. This is generally called structured data, for example, taking the application that we are building to store the credentials, we might want to store users separately and other information related to the credentialsin a separate table.
We can have these columns in the users table:
user_id, username, created_by, created_at, updated_by, updated_at

Visual Image for users table in RDB
and we can have the following columns for the credentials table:
website_id, website_name ,password, user_id,description , created_at, updated_by, updated_at

Visual Image for credentials table in RDB
where we can make user_id a foreign key and link it to the user’s table.
What is a major drawback in RDBMS data modeling?
For our small application, this is a very simple example and user_id can be considered as one duplicate data column. But think about a large application like e-commerce where there are so many entities involved, and linking the entities according to our application increases duplication.
For accessing the table which involves 2 or more tables, relational databases have a concept of joins, which are very powerful and it gives you what you want with a single query. But the problem is these are very slow, join operations have to scan the whole database and when there is a huge amount of data, these perform slower.
Data Modeling with DynamoDB
Alright, since we have used DynamoDB in our application, let’s see how to model the database. When we talk about DynamoDB, the most important thing is to use as less tables as possible, or even just a single table for a simple application or a sub-feature of a big application. This is called single-table design and it’s very efficient in terms of performance.
For people who have extensively used Relational Databases, getting used to single table design takes some time, and it becomes slightly difficult to model the data especially if you are new to this. But having said that, practice makes a man perfect, once you get used to it, you’ll get a taste of it.
The major difference between Relational Database modeling and single table design is that in the single table design, we have to think about most of the accessing patterns before building the application, whereas in RDB you can create a table as and when needed after initial data model is created. Since this is a challenging aspect, the single table design needs some brainstorming before getting started. Also, it’s like coding, unlikely to get the desired results on the first go, hence the design needs some reviewing and some iterations before we get started. The single table design is tightly coupled with the application.
My first single table design
While modeling with the DynamoDB, or coming up with a single table design, the most important thing is to think about the access patterns of fetching the data, to think about how our application fits those access patterns while interacting with DB. Think of these like queries in plain text, for example: fetching the list of credentials for a specific user This is an access pattern, when you note down all the access patterns that are required for your application, you will have 50 percent of the problem solved, and when you design the table, you will see how handy these can be.
Once the access patterns are in place, you can decide on which attribute to make a primary key and which all can be made indexes. We had spoken about these terms in my previous article, if you haven’t read it check this out: All you need to know about the Amazon DynamoDB
My first table was horrible, it had so many flaws because I did not come up with access patterns, but when I went in the correct flow, access patterns helped a lot.
These are the access patterns I noted down.

Access Patterns for DDB Modeling
I am calling my Password Manager as EzyPass, it will be live soon and I am thinking of making it open-source. If you look at the above table, you can see I have divided them according to entities, which means, before coming up with access patterns, it is better to have a high-level design for the entities you want to consider in your application, this is common even in RDBs.
I created the following entity diagram to get started with the single table design
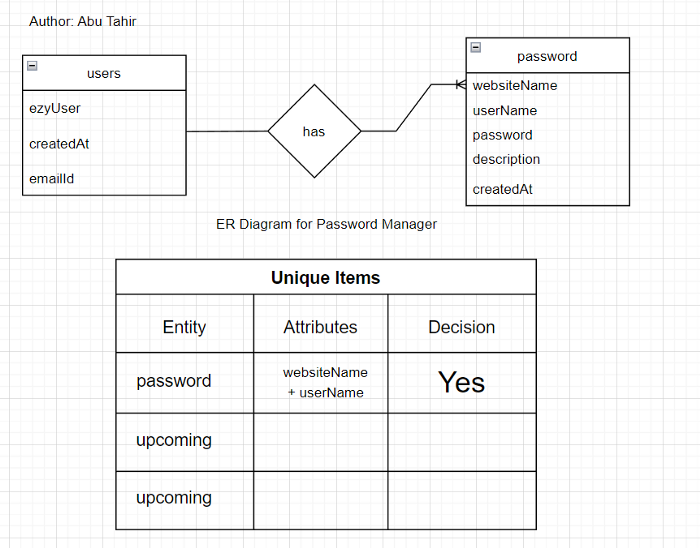
Entity-Relationship Diagram for Password Manager
The upcoming is for the upcoming features in the plan, but for now, we have these entities and we can go with this. As you can see, just by having these two things in hand, we now have a whole blueprint of our application.
I have added Params and Notes in the access patterns image above, params are for the APIs that we are going to create, I haven’t filled them completely and the notes are for specific things we have in mind and to be given a thought about.
At first, I went ahead with having the user_name as primary key, but it turns out that for every user, there can be multiple websites, so if we try to add the data to DynamoDB using user_name, the previous record will get overwritten because it’s a PK.
Hence I had to consider a composite key, which means a primary key with the combination of partition-key and sort-key.
Also, in our application, the user_name for the registered user is one attribute, and the credentials he stores can also have a user_name for that particular website, so I made ezy_user an index to fetch the records of a particular logged-in user. But I think storing the email instead of user_name makes more sense, what do you think? You can comment and let me know.
So finally after I came up with the above things, I had to think about some scenarios that can happen while the data is getting inserted and came up with the below simulation.

Simulation of how data can be stored in DB
As you can see, the major concern I had was storing multiple websites and their credentials for a particular user, and in the above image, it’s resolved. The ezy_user tahir has multiple credentials stored. Also, I have not added the remaining columns like description, created_at, etc. since the important columns that needed simulation were the above specified in the image.
And the last one was a simple decision to be made, I finalized user_name to be the partition key and website_name to be the sort key. And this is how I finalized the data modeling with DynamoDB.

Primary key planning
The above-shown images are the final iterations for my DynamoDB model, the previous one was the below image, which is horrible and doesn’t solve any use major use cases.
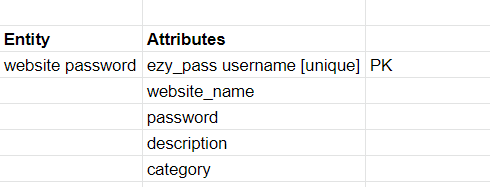
The first iteration I did
The iterations I made can be enhanced and we can add more features to it, it is always better to create ER-Diagrams, then come up with Access Patterns, and finally Simulation. If you are planning to add more features to it, you can come up with more entities and more access patterns and model your DB.
If you want to gain more knowledge about DynamoDb and Data Modeling, you can get this book here: The DynamoDB Book by Alex DeBrie. This is one of the best books you can read to get a thorough knowledge of Amazon DynamoDB.
Conclusion
First of all, thank you for spending your valuable time on this article, I really appreciate it.
In this blog we took a deep dive into DynamoDB data modeling, we also learned about data modeling with RDBs, and we learned what is a single table design and why it is important. Also, my story of data modeling with DynamoDB, and how I came up with a final data model, In the next article, I will show you how to deploy the DynamoDB resource to the AWS console with Serverless Framework and we will get started with the implementation part of our application.
Thanks for reading. Have a nice day :)